The db_object and db_object_child models are capable of writing all file changes to a log file, also known as an audit trail. Unlike internal logs maintained by the database, these logs are intended to be used at the application level to allow end users or auditors to ascertain when certain table rows were changed, what values were updated and who applied the changes.
The audit trail tables generally contain all of the important fields that are defined on the tables being audited. Additionally, these tables should contain important information required for auditing purposes. These fields will vary by company and by the sensitivity of the tables being audited. Typically these fields will include information such as:
- The date and time the change occurred
- The event or action that triggered the change
- The user who made the change
The purpose of the db_log_profile model is to define the names of the audit-related fields to be included in the audit tables as well as the audit values that are to be assigned to these fields.
Sharing db_log_profile Definitions
It is quite likely that several applications will have similar logging requirements. For this reason, it is a good idea to define your log profiles within the pseudo site system so that they can be easily shared by any number of other applications. On the other hand, if the logging requirements for a given application are quite distinct or unique, it is best to define the db_log_profile definitions within the application itself.
Logging Methodologies
There are two main methodologies that can be followed when defining your log files:
- Generic Log Files
- Table Specific Log Files
With the generic approach you could conceivably just have two log files in total, one for logging header tables and one for logging detail (dependent child tables). With this methodology the column values related to the data being changed must be stored using JSON format in a common field. The advantage of this approach is that you only need to have two dedicated logging tables. It also makes it easier to monitor activity at a higher level. For example, a simple query could tell you which tables a certain user has updated or who made changes to any table over a certain time period.
With the Specific Log File approach, you typically define a separate log table for each table being logged. This approach involves creating a lot more log tables and pages to browse these tables. This is the better option if you want to search for specific values within the log tables since the fields are not stored as JSON which can't be queried very easily.
It is also possible to deploy a combination of generic and specific logging. With this approach, you could have specific log fields for important columns while using JSON to store values that are less important.
Header Table vs. Dependent Table Logging
Recall that a db_object definition consists of a header file and any number of detail files (dependent tables). For example, an order object might be comprised of an order_header table and an order_lines table. Currently, child tables cannot be logged unless the header table is logged. Nevertheless, it is possible to log only the header table and not the dependent table(s). You can also log the header table and just some of the dependent tables.
Normally, the set of fields that you define for logging the header file are more extensive than those used to log dependent tables. This is because both tables must contain an identifier that is used to join the header with the detail. Therefore, if you log say the user id who made the change at the header level then you can establish an SQL join to obtain this information rather than redundantly storing it for each detail log row.
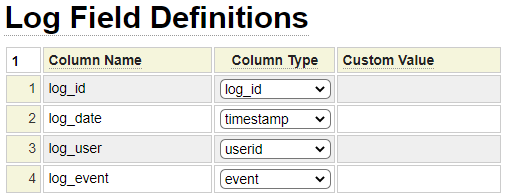
Available Log File Columns
Here we see a comprehensive set of log columns defined:

In most cases you will not require so many fields on your log files. Some of these columns will typically only be used when following a Generic Log File methodology.
Column 1 contains the names that you have used on your log file. In the example, we prefix all of the fields with log. Although this is not necessary, it is a good way to differentiate these fields from the column that will be used to store the updated or removed database field values.
Column 2 is used to specify what value you want to be stored to the log field column. In the following section we will describe each of these options.
Log File Column Types
action
Action is primarily used when logging dependent (child) records. This can contain insert, update or delete. Note that the event log field reflects the maintenance event from the perspective of the object as a whole. For example, when performing an update event on an object, it is possible to delete certain child rows, update some rows and insert other rows. In all of these cases the event will be logged as update whereas the action will reflect the child action that occurred.
child_row
This field only applies to log files designed for logging child (dependent) tables. This reflects the row number of the child row that was modified. Note that this row number may not be unique since when a primary key is updated on a child row this is implemented using a delete followed by an insert. Both of these log records would end up with the same row number.
custom
Custom fields allow you to specify a custom value to be written to the database column. The custom value is entered in column 3. This can be a static value but in most cases custom values will contain dollar functions in order to provide dynamic content.
event
This is the event from the perspective of the object. By default this can contain insert, update or delete however custom events such as post, pay, cancel, etc. are also possible by calling $this->assign_config('event','event_name') within one of the db_object methods.
function
This can be used to populate the field using a database function. Enter the function to be used in the custom value column.
ip_address
Use this value to populate the field with the update user's IP address. Note that IP addresses can be spoofed so they my not accurately reflect the IP address of the user.
key
This is used to save the key value of the record. This is mainly used as part of a generic logging methodology. For compound keys you can use the custom value column to supply a separator character to be used between the different key components. For dependent tables, the key value reflects the key that is used by the primary (header) file.
key_json
This field can be used to write out the key component values in JSON format. This is mainly used as part of a generic logging methodology.
log_id
You must define exactly one column of type log_id. On header log files, this should be defined as an auto-generated integer that is automatically incremented by the database. For dependent log tables this should be defined as an integer with Not-Null restrictions (and not auto-incremented). This column is used to link the audit records of an object header with those of the child rows.
non_key_json
If you don't want to define individual fields to log all of the values that were changed on the table being logged, non_key_json can be used to log the key field values in a generic way. This is mainly used as part of a generic logging methodology.
object_name
This is the name of the db_object class that performed the updates being logged.
page_id
This is the name of the web page that performed the updates.
row_json
This combines the key columns and the non-key columns in one JSON string. This is mainly used as part of a generic logging methodology.
site_directory
This is the site directory at the time that the updates took place.
table_name
This is the name of the table being logged. Again, this would only tend to be used in a generic logging approach since in a non-generic methodology there is normally only one table associated with each log file.
timestamp
This is the date and time that the update (or delete or insert) occurred.
user_agent
This is the user agent supplied by the browser. This describes things such as the type of browser and device being used.
userid
In most cases logging is performed for applications that require a logon since one of the main purposes of the log is to find out who made a particular change. This field contains the id of the logged in user.
Designating Which Table Columns to be Logged
It is not necessary to define all of the columns on the table being logged on the corresponding log file. If you are taking a generic logging approach, you do not have to define any table-specific columns. If you are defining dedicated log files for each table you can decide whether to log all columns or just the most important or sensitive columns.
Begin by setting the default behaviour using the Log Column Option.

Next we describe the significance of each option.
Include
This option should be used as the default when you plan to log most of the table fields using dedicated log columns. This setting can be overridden at the field level if you don't want to log certain fields. The field level option can also specify log:json if you don't have a dedicated field for the column but you have a generic JSON field indicated on the log file.
Exclude
Use this default if most of the columns will not be logged using dedicated log columns. Use the log property at the field level to log just the selected fields. For the fields that have dedicated columns on the log file, use log:true. If you want to log certain columns in a combined JSON field, use log:json.
Include as JSON
Select this option to implement a generic logging strategy where most fields are logged using one of the generic JSON column settings (key_json, non_key_json or row_json). The setting specified here can also be overridden at the field level.
Logging Example 1 - Dedicated Log Table
Consider the following db_object_model definition:

Let's review the key logging settings.
Log File Schema
If the log tables are stored in a separate database, enter the schema name for the database here. This defaults to the same schema as the table being logged.
Log Table Name
Enter the name of the table to be used to store the log data.
Log Update Type
Indicate whether all fields should be logged, regardless of whether they were changed, or only changed fields. Note that if you plan to only log fields that are changed, the unchanged columns will be stored in the database as NULL and therefore can't be defined as Not-Null. Furthermore, if a value is changed from a non-null value to a null-value it will be difficult to ascertain that this has happened since the NULL value will be stored in the log just as is done for fields that are not changed.
Log Column Option
In this example we are using a dedicated log file so we set the default log option to include.
Log Profile
This profile defines the generic columns to be written to the log file.
DB Column Parms
In this example, we don't want to log the film description and original_language_id columns so we have overridden the log setting at the field level.
Example 2 - Generic Logging Approach
Consider the following example settings using in the actor db_object.

Notice in this example, we are using a generic log table. This table should contain a generic field to store the updated values. For example, one of the columns should be mapped to column type row_json. We have set the default Log Column Option to Include as JSON. Since First Name and Last Name are derived columns we are overriding the log settings for these columns so they will not be written to the generated JSON values.