For most sites it will not be necessary to define an xml_sitemap explicitly. This is because all sites inherit the system page sitemapindex.xml. You will need to identify this page to Google and other search engines to help them crawl your site fully. Note that this default sitemap is automatically referenced in the default robots.txt file that is also inherited from system.
Making Sure the Correct Pages are Indexed
Consider the following page properties and Advanced Properties:

The following properties influence whether pages are added to the default xml sitemap.
Page Type
All page types except Transaction Next, Page Component and Desktop Alternative will be candidates for adding to the default xml sitemap.
Allow URL Access
Allow URL Access must be set to Yes in order to be included in the default xml sitemap.
Login Required
Pages that require a login in order to be accessed will not be included in the default xml sitemap.
Noindex
If the Noindex flag is checked, the page will not be included in the xml sitemap. Be sure to check this flag if pages appear in your default xml sitemap that you do not want to be indexed by search engines.
Redirect To
If a Redirect To value is specified the page will not be included in the default xml sitemap.
Other Fields that Influence the Generated XML Sitemap
The following fields are optional but can be set to add specificity to the generated sitemaps. These fields are not used for any other purpose.

Change Frequency
Change Frequency is used to give search engines a hint about how often they should crawl the page. If you have pages that show "live" data, such as stock prices, you could set the change frequency to always. Other pages should be set according to how often you think they will be updated.
Page Priority
This field gives search engines guidance on the relative importance of the different pages of your site. Search engines don't define exactly how this settling will be used.
XML Sitemap Structure
The default structure of the sitemapindex.xml output is shown here.
<?xml version="1.0" encoding="UTF-8" standalone="no" ?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap>
<loc>https://www.example.ca/sitemap_main.xml</loc>
</sitemap>
</sitemapindex>Notice that this is actually an index of one or more sitemaps. The main index is generated by the inherited page sitemap_main.xml which is loaded from system.
Using the xml_sitemap model
As mentioned previously, many websites will not need to use the xml_sitemap model because the default behavior inherited from system will generate the desired xml sitemap automatically. Nevertheless, it is important to review the default sitemap to make sure that it does not contain any pages that you do not want to be indexed by search engines. If you identify pages in your default xml sitemap that you want to have removed you can simply set the noindex property for these pages.
The main purpose of the xml_sitemap model is to add pages to your sitemap that are not automatically generated. There are three main types of page URLs that may not be generated into the default xml sitemap.
- Pages that are inherited from other sites
- Pages that render several URLs
- Pages that are defined using GenHelm's database driven blogging system (see Adding Additional Sitemaps below)
Inherited Pages
Recall that one of the powerful features of the GenHelm runtime framework is that it allows pages to be loaded from an inherited site. For example, if you host several restaurant sites, you could create a pseudo site called restaurant which could contain common pages that might be used in several different specific restaurant sites. In order to use these shared pages the specific sites simply need to set restaurant as "Inherit From Site" value in site_settings.
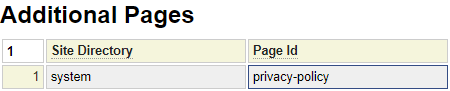
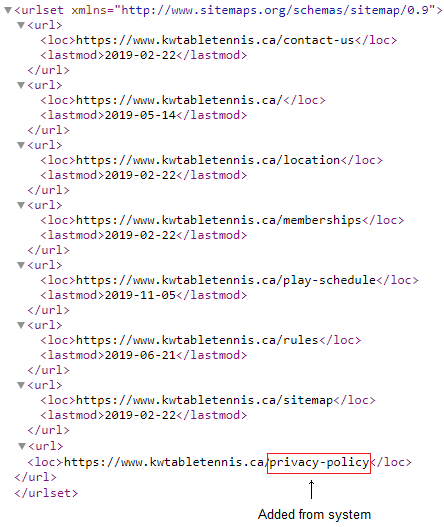
In a similar way, all sites inherit from the system site. One of the pages available in system is a boiler plate Privacy Policy that could be used on many different sites. To do so you simply need to use $link(privacy-policy) from any site on the server to create a link to this page.
When inheriting pages in this manner, the pages are not automatically included in the site's default xml sitemap. Instead, you must explicitly reference these inherited pages by using the xml_sitemap model.
Pages that Give Rise to Several URLs
Consider a page named shop-by-type. This page takes a url parameter named type as shown here:

Notice this URL Parameter is not formatted as you would expect in that most URL parameters are passed as name=value. URL parameters formatted in this way can take their value from folder based URLs. For example, consider the URL:
www.example.com/shop-by-type/electronics
When attempting to reconcile this URL, the GenHelm framework will first look for a page named shop-by-type/electronics. If such a page is not found, the framework will next look for a page shop-by-type. If this page is found and if the page defines URL parameters (without equal signs) it will populate the querystring with the subfolder name in the URL. So, internally, this will be the same as executing the following URL:
www.example.com/shop-by-type?type=electronics
In a similar way, there could be several folders that resolve to querystring parameters. For a more detailed explanation of this feature please follow this link which describes how URL folder names can be converted to parameters.
Now, getting back to our xml_sitemap model, this would be an example where one page could lead to dozens of entries in the sitemap xml. The purpose of the xml_sitemap model is to add these extra entries that don't get included by default. Here we see an example of an xml_sitemap definition:

Referring to this definition we can see that the shop-by-type page will generate 15 separate entries in the xml sitemap. Since the shop-by-type page defines a URL Parameters value of type, these entries will be shown as folder-based URLs rather than passing the type explicitly in the querystring.
It is also worth noting that the page shop-by-type (all by itself without parameters or subfolders) will not be included in the xml sitemap by default since this page is indicated as requiring a type parameter.
Naming the xml_sitemap definition
The default name for your xml_sitemap spec is sitemap_main. Be sure to use this name for your main sitemap specification otherwise it will not be used by the xml sitemap builder.
Adjusting the Generated Page List
Occasionally, there may be times when you need to adjust the pages that are generated by the default xml sitemap handling. In these cases it is possible to provide a class name in the Dynamic Modifications Class field. The update_pages method of this class will be called after the main sitemap pages have been built and it is able to add or remove pages as necessary. Here is an example of such a class:
class tweak_xml_sitemap
{
//custom function + {
function update_pages ($collector, & $url_list) {
$collector->add_page('blog','blog_seq=4');
$collector->remove_page('custom-tarps');
}
//custom }
}Notice that the class is passed an instance of the collector object. It can call the add_page method of this object to add new pages to the xml sitemap and call the remove_page method to remove pages from the default xml sitemap. Here are the signatures of these methods as well as other methods used to add and remove documents (non-standard pages).
function add_page($page, $querystring='',$sitedirectory='',$priority=null,$changefreq=null,$lastmod=null)
function remove_page($page, $querystring='')
function add_document($filename,$priority=null,$changefreq=null)
function remove_document($filename)Adding Additional Sitemaps
Recall that sitemapindex.xml defines an index of sitemaps. For most sites you will only have one entry in this index (which is sitemap_main.xml). For larger sites you can introduce additional sitemaps. A common example would be for sites that have database driven blogs. In this cases you would need a custom "page" to generate the index of all of the blog pages. In fact, such a page exists in system to support the default database driven blog that comes with GenHelm. Here we see how this page is referenced to generate a second xml sitemap which will list all of the dynamic blog pages.

Here we show what your generated sitemap will look like after adding the blog_sitemap page:
<?xml version="1.0" encoding="UTF-8" standalone="no" ?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap>
<loc>https://www.genhelm.com/sitemap_main.xml</loc>
</sitemap>
<sitemap>
<loc>https://www.genhelm.com/blog_sitemap.xml</loc>
</sitemap>
</sitemapindex>By default, the blog_sitemap will include links to category pages and post lists. If you only have a small number of database blog pages these index pages may not be desirable to index since they won't have much content. You can prevent these pages from being exposed in the sitemap by adding exclude_category_page=true&exclude_category_post_page=true to the querystring as shown here.

In the example above we also show that you can pass a specific to the blog_sitemap page if you only want to index certain topics.
If you only want to index a few specific blog pages you don't need to use blog_sitemap at all. Instead you can add the post page for each post you want to index. You will need to include the topic and post node in the Querystring as shown here.

If your site contains other dynamically generated pages you can use blog_sitemap as an example showing how to create additional sitemaps you may require.